
Machine Learning: o que é e como aplicá-lo ao Marketing Digital
Última revisão:
Out 2024

Aprox.
38 min de leitura

Introdução
Veículos autônomos que já circulam pelas ruas e estradas, aviões que voam a maior parte do tempo de forma autônoma, feed das redes sociais com conteúdos selecionados para cada usuário, recomendações personalizadas de filmes, músicas e produtos, além da caixa de entrada livre de spam.
Eis alguns exemplos que provam não só a capacidade de aprendizado das máquinas, mas também o quanto o Machine Learning já é uma realidade entre nós.
Engana-se se você acredita que essa tecnologia é tema para gigantes, como Facebook, Netflix, Spotify e Google. Esclarecer o que é Machine Learning e mostrar as aplicações dessa tecnologia para o Marketing Digital são alguns dos objetivos deste eBook, produzido pela Resultados Digitais, líder no desenvolvimento de softwares (SaaS) voltados para o crescimento de pequenas e médias empresas, em parceria com a Prestus, especializada no atendimento telefônico receptivo (geração de leads / SDR) e ativos (prospecção de leads/BDR).
Aqui você também encontrará um tutorial de Machine Learning para predizer quais Leads têm mais chances de se tornarem seus clientes, o que aumenta as suas oportunidades de negócios. Você irá descobrir que, além dos Leads A, também há muitos Leads bons entre aqueles com perfil C e D. É o segredo que faltava para você focar esforços e fechar mais vendas. Conte com a gente nessa jornada!
O que é Machine Learning
O aprendizado de máquina (em inglês, machine learning) é a capacidade dos computadores identificarem padrões entre um mar de dados e, a partir dessas informações, fazerem previsões com alta precisão. Para isso, eles lançam mão de algoritmos e técnicas estatísticas.
O conceito de Machine Learning está baseado na ideia de que os equipamentos são capazes de aprender com os dados, reconhecer padrões e tomar decisões com o mínimo de programação.
O Machine Learning é uma vertente da inteligência artificial. Sobre essa relação, Avinash Kaushik, uma das referências mundiais em web analytics, tem uma explicação fácil de entender:
- Inteligência Artificial: é o nome mais amplo da matéria. A partir daqui muita coisa pode se desdobrar. É como falar de Marketing, sem especificar qual tipo estamos tratando.
- Machine Learning: habilidade da máquina ou sistema aprender sem necessidade de programação
Buscar padrões não é algo inédito para a humanidade. Identificar o comportamento das estações do ano e das plantas proporcionou ao homem cultivar as espécies certas para cada época, garantindo a subsistência e sobrevivência da sociedade.
Mais recentemente, políticos tentam reconhecer padrões na opinião pública para elaborar discursos e economistas se debruçam sobre a evolução dos indicadores econômicos para antecipar cenários críticos ou promissores.
“O que é novo é o aumento desconcertante da possibilidade de encontrar padrões nas informações”, afirmam os autores do livro Data Mining, Ian H. Witten, Eibe Frank, Mark A. Hall e Christopher J. Pal. Lidar com tamanha quantidade e complexidade de dados — estima-se que a quantidade de informações armazenadas no mundo dobre a cada 20 meses — só é possível graças a ajuda das máquinas.
Os benefícios do Machine Learning para o seu negócio
O volume crescente de informações combinado à evolução constante da tecnologia proporciona análises cada vez mais precisas e rápidas. Resultado: a capacidade das organizações encontrarem oportunidades lucrativas aumenta.
“Informações analisadas inteligentemente são recursos valiosos. Elas podem proporcionar novos insights, melhores decisões e, no âmbito comercial, vantagens competitivas”, completam os autores de Data Mining.
Graças ao Machine Learning, sistemas financeiros e governos podem identificar fraudes rapidamente, enquanto ecommerces e redes varejistas conseguem vender mais a partir de recomendações de novos itens aos consumidores.
Segmentos tradicionais como as indústrias recorrem ao ML para garantir que haverá a quantidade ideal de matéria-prima na fábrica e que os caminhões saiam recheados de produtos na manhã seguinte. Enquanto isso, transportadoras aproveitam as rotas mais eficientes e econômicas identificadas pela tecnologia.
No Marketing Digital, as oportunidades oferecidas pelos sistemas de aprendizado de máquina também são inúmeras e promissoras, mas esse é assunto para o próximo tópico.
As aplicações do Machine Learning no Marketing Digital
É natural que o Marketing se apoie no Machine Learning à medida que se torna uma área cada vez mais precisa e dependente dos dados para provar seus resultados. Sendo assim, listamos abaixo alguns usos do Machine Learning que têm feito com que o Marketing Digital, especialmente, prove o seu valor:
Qualificação de Leads: a mensuração das contribuições do time de marketing no aumento da receita da empresa está se tornando cada vez mais precisa e rápida, graças à análise de dados e ao Machine Learning. Saber o que está gerando mais Marketing Qualified Leads (MQLs) e Sales Qualified Leads (SQL) é apenas um dos muitos benefícios que o Machine Learning traz ao marketing. O Machine Learning ajuda a qualificar de forma muito precisa as listas de clientes e os prospects, usando dados relevantes disponíveis online. Assim, eles podem construir um ideal customer profile (ICP). E, a cada venda feita, os dados vão sendo atualizados, melhorando o prognóstico de novas possíveis vendas, ajudando os vendedores e pré-vendedores a economizarem tempo, priorizarem os leads mais qualificados, canalizarem os esforços de vendas para os locais e estratégias corretas.
Anúncios ainda mais certeiros: o Machine Learning também pode ajudar a criar anúncios cada vez mais personalizados e específicos para determinada pessoa. Como? A ideia é que, a partir das informações que você fornecer para criar os anúncios, como títulos e descrições, o Machine Learning seja capaz de interpretar quais combinações fazem mais sentido para determinado perfil de cliente de acordo com as informações que ele também fornece na web (isso inclui seus dados e também seu comportamento na internet, por exemplo, sites que ele visita, onde ele clica etc.) Até mesmo o Google já anunciou que quer criar mecanismos para melhorar os anúncios criados a partir de sua plataforma por meio do Machine Learning.
Chatbot: quem não gosta dos simpáticos chatbots? Pois eles também se utilizam do Machine Learning para auxiliar um visitante em determinado site. Os chamados bots de serviço ao cliente podem usar o processamento de linguagem natural e os dados de atendimento ao cliente para responder perguntas comuns e melhorar a qualidade dessas respostas ao longo do tempo.
Sistema de recomendação: algumas vezes, pode até parecer que a Amazon, Netflix e Spotify não entendem muitos dos nossos gostos, não é mesmo? Mas a verdade é que os mecanismos de recomendação online utilizados por essas plataformas são sim bons exemplos de como funciona o Machine Learning. Isso porque eles utilizam os dados coletados por milhões de usuários e compradores e, a partir daí, podem prever itens que você possivelmente gostará, de acordo com suas compras anteriores, seus hábitos de visualização, e as correlações mais comuns entre os usuários.
Conteúdos que engajam: por meio do Big Data, o Machine Learning pode analisar dados, criar novas ideias e ajudar a construir uma estratégia de conteúdo personalizada, o que significa que os profissionais de marketing de conteúdo podem ter mais chances de criar conteúdo mais eficiente, personalizado e que gere mais valor, e também que seja mais fácil de encontrar pelos mecanismos de busca. Por exemplo: ferramentas de ML podem analisar as estratégias de concorrentes e o comportamento dos usuários para determinar qual é a melhor abordagem para engajar possíveis clientes. Isso permite que o ML encontre conteúdo com capacidade de viralidade e com qualidade para uma audiência específica. O resultado é um conteúdo que atinge seu público em cheio, o que gera mais engajamento e resultados.
Evitar o churn: o temido churn também pode ser impactado (positivamente) pelo ML. Um exemplo: em vez de depender de abordagem caras e demoradas para minimizá-lo, o Machine Learning usa modelos de risco para ajudar a determinar como ações para evitar o churn geram, de fato, resultados. Isso permite que os profissionais levem em consideração quando e como devem intervir para reduzir a probabilidade de churn, e também para calcular o lifetime value (CLV).
Como o Machine Learning funciona
Dissemos que o Machine Learning usa algoritmos para analisar os dados, reconhecer padrões e, a partir disso, fazer previsões, dispensando a interação humana. Mas como toda essa engenharia acontece? Existem alguns métodos para as máquinas aprenderem a identificar modelos. Falaremos sobre três principais modos:
- Aprendizado supervisionado: neste tipo de aprendizagem, o computador precisa de um “professor”. De forma simples, imagine que você possui uma empresa de turismo e quer ensinar ao computador a reconhecer fotos de praias, destino que atrai muitos clientes na sua agência. O seu trabalho seria inserir no sistema do computador um conjunto de imagens: algumas com a tag (ou rótulo, como costumam chamar os programadores) “praia” e outras com a tag “não-praia”. Espera-se que o algoritmo aprenda e identifique padrões entre as imagens com mar e areia e reconheça a próxima vez que tiver contato com uma delas. Seu portfólio de destinos tende a aumentar e muito!
- Aprendizado não-supervisionado: neste caso, você apenas insere um conjunto de imagens, sem identificar ao computador quais são de praia. O trabalho do sistema é identificar padrões entre as fotos e descobrir o que está sendo exibido. O objetivo desse tipo de aprendizado é forçar o computador a achar padrões entre um conjunto de dados. Na prática, essa estratégia é útil para encontrar características e interesses similares entre segmentos de clientes, por exemplo.
- Aprendizado por reforço: novamente de forma simplista, o computador pode ser comparado a um jogador de videogame, que aprende por tentativa e erro até atingir o objetivo final. Nesse tipo de aprendizagem, ensina-se ao computador qual ação deve ser priorizada num determinado contexto. Para isso, os possíveis resultados estão relacionados a recompensas e punições.
Em tempo
O Google desenvolveu o Teachable Machine, um site para você se familiarizar com os princípios básicos de Machine Learning. Por meio de três botões coloridos, você treina o computador utilizando expressões faciais e gestos. É grátis e precisa de acesso a sua câmera. O vídeos abaixo foi desenvolvido pela empresa e o áudio está em inglês, mas as imagens dizem por si só. Confira!
Outro recurso bastante interessante para entender Machine Learning é o Tensor Flow. Mais técnico, ele mostra como uma máquina “pensa” por meio de “neurônios”. Clique à vontade.
Vá além do Lead Scoring: descubra neste passo a passo quais Leads têm potencial para se tornarem seus clientes
É hora de ver na prática como aplicar o ML ao Marketing Digital da sua empresa. Elaboramos um tutorial que usa o aprendizado de máquina para predizer quais Leads têm mais chances de se tornarem seus clientes. São apenas cinco passos! Ao final deste capítulo, a intenção é que você esteja preparado para aplicar o que aprendeu imediatamente.
Para fins didáticos, nos exemplos deste eBook usaremos a ferramenta KNIME, que está disponível sob licença GNU GPL, a mesma do Linux. Isso significa que você pode utilizá-la no marketing da sua empresa sem custos.
É sempre válido estudar os termos de uso da ferramenta, especialmente se você quiser revender software que envolva licença GNU. Nesses casos, o uso pode não ser livre. Assim como o KNIME, há outras ferramentas de ML que você pode utilizar, como Orange ou mesmo scripts em Python.
Como apoio à próxima sessão, você pode assistir ao tutorial no vídeo abaixo, antes de começar a ler suas explicações e dicas detalhadas.
Passo 1: Coletar os dados do BigData e importá-los no KNIME
Não importa se os seus dados estão numa tabela simples, no Excel, num banco de dados relacional, como MySQL, Access ou Amazon AWS, ou mesmo num sistema integrado de marketing como o RD Station Marketing. O primeiro passo é consolidar tudo o que você conhece de um cadastro em uma única tabela. Esse é um bom momento para você criar alguns campos adicionais no seu arquivo.
Exemplo 1: criação de um campo DDD
Digamos que você tem dois campos de telefone: “Telefone com DDD” e “Celular com DDD”. Você pode criar um campo calculado e chamá-lo de “DDD”. Para isso, no Excel, utiliza-se a fórmula abaixo:

Exemplo 2: uso do CEP para segmentar a base de forma simples
Caso você possua o CEP dos seus contatos, pode usar o primeiro dígito do código postal para agrupar os estados em macrorregiões econômicas, conforme a figura abaixo.

Poderá haver campos que contêm mais informações do que é necessário. Por exemplo: em vez de usar um campo que lista qual CRM os clientes utilizam (o que pode gerar respostas variadas), é interessante criar um campo que classifica com 1 ou 0 quem usa ou não esse tipo de recurso. Isso permitirá ao ML testar se esta informação é importante para todas ou eventualmente uma única categoria. Você pode fazer essa alteração no Excel ou por meio de uma substituição no KNIME.
Revisados os campos da tabela, é hora de importar as informações na ferramenta de Machine Learning. Ela é fácil de usar e funciona segundo um “fluxo” de dados” composto por nós, que vão da esquerda para a direita. Eles são ilustrados pelos pequenos bloquinhos coloridos na figura abaixo.

Os nós têm funções específicas:
- Os blocos iniciais importam os dados de um arquivo ou base de dados externa (Big Data).
- Em seguida, os nós da região chamada de “Pré-processamento” fazem o tratamento de algumas colunas, de modo a deixar os dados preparados para a fase seguinte de aprendizagem.
- Na fase de treinamento do modelo, teremos o nó principal do ML: o Decision Tree Learner. Ele será treinado a partir dos dados históricos e criará parâmetros que orientarão a decisão sobre qualquer cadastro, inclusive os novos que surgirem.
- Estes parâmetros serão finalmente injetados num nó chamado “Decision Tree Predictor”, que estimará a probabilidade percentual daquele cadastro se tornar um cliente.
- Finalmente, à direita da figura acima, temos alguns nós que nos ajudarão a exportar os dados e avaliar o modelo.
A grande vantagem de se trabalhar com fluxos é precisar desenhá-los apenas uma vez. Sempre que você trocar o arquivo Excel, o fluxo será executado novamente de maneira automática.
Para começar a montar o seu fluxo, o primeiro nó a ser usado é o “Excel Reader”, localizado no painel “Node Repository” (Repositório de Nós ou Componentes) de busca do KNIME, ilustrado na figura abaixo.


Este componente irá fazer a importação dos dados (Excel) para dentro das tabelas internas do ML. Clicando duas vezes sobre o ícone, vemos as opções do nó, onde destacamos os seguintes ajustes:
Em “Select the sheet to read”, você deve selecionar em qual dos TAB’s (sheets) do arquivo os dados estão. Em “Row IDs”, selecione “Generate RowIDs” para que a própria ferramenta crie uma coluna extra com valores únicos e crescentes.

Feita a configuração, clique em “OK” e volte à tela principal da ferramenta. Em seguida, selecione o ícone Execute Selected Node, o primeiro botão verde do menu do KNIME. Ele verifica se há algum erro no console. Se houver, corrija os dados no Excel e recomece o processo.
Agora é hora de excluir da base de dados as colunas que induzem a conclusões erradas.
Exemplo: ter um campo “faturamento atual” identificando o valor que o cliente paga à empresa atrapalha a análise. O aprendizado de máquina irá descobrir rapidamente que este é um ótimo campo para estimar se um cadastro é cliente ou não. Lembre-se: o objetivo aqui é identificar se um cadastro irá ou não se tornar cliente no futuro.
Use o componente “Column Filter” (filtragem de colunas) para selecionar as colunas que deseja serem analisadas. Para isso, vá até o Node Repository, selecione o componente “Column Filter” e o arraste até o fluxo com o mouse. Conecte os dados lidos à entrada do componente, e conecte sua saída com o próximo nó, para que o processo continue.

Vale a dica
Não exclua um campo apenas por acreditar que ele não faz sentido para a predição. O ML nos surpreende com conclusões a que não chegaríamos sozinhos.
Veja este exemplo: imagine que na sua tabela há um campo que registra a origem dos Leads, como busca orgânica, busca paga, referência, e-mail etc.
Você pode pensar que não faz diferença se um advogado baixou seus materiais a partir do clique em um anúncio ou no link do seu site, mas o ML é capaz de encontrar padrões de comportamento que você jamais imaginaria. O aprendizado de máquina pode, por exemplo, identificar que o campo origem é importante para Leads do segmento de direito, mas irrelevante para empresas de serviço.
Passo 2: Pré-processamento dos dados usando KNIME
A primeira decisão nesta fase diz respeito ao campo que você gostaria de prever. Se quero descobrir, por exemplo, dentre os Leads de minha base, quais têm mais chance de contratar o serviço de SDR da Prestus, o campo escolhido deve ser aquele que informa se o contato é um Lead (ainda não contratou o seu serviço) ou um Cliente. É neste campo que o algoritmo de machine learning vai parametrizar e aprender a prever.
Para isso, o algoritmo usará a base de dados histórica, analisando os contatos que viraram clientes e buscando padrões nos demais campos, de forma a predizer corretamente isso. Lembrando que o algoritmo não acertará todos os casos, mas a ideia é encontrar padrões estatísticos e não certezas.
Talvez você se pergunte: “se o algoritmo for realmente bom, ele dirá que todos os meus cadastros são o que realmente são: Leads são Leads, e clientes são clientes; o que eu ganho com isso?”. De fato é possível que ele conclua que isso é o mais provável, mas o detalhe é que ele sempre informará duas probabilidades: a de ser Lead e a de ser cliente. E você poderá atuar sobre os leads com probabilidades a partir de poucos pontos percentuais (2% ou 3%, por exemplo)
Quando você tem uma lista de probabilidades, ainda que baixas, de um Lead se tornar cliente, poderá ordená-la da maior para a menor e estabelecer uma “régua” para que o marketing entregue esses contatos para vendas. Assim, alguns deles viram Leads qualificados a partir da análise de machine learning que você fez.
Estatística em Marketing e Vendas
Se você gosta de estatística, leia esta seção (caso contrário, pode pular).
Os algoritmos de Machine Learning buscam ao máximo fazer previsões acertadas e, quando erram, eles se autopenalizam, alterando parâmetros de aprendizagem para que não errem novamente em próximas previsões. Com isso, vão otimizando os milhares de parâmetros internos, até conseguirem errar menos.
Digamos que você queira que um sistema de ML preveja, dentre todos os visitantes que navegaram e baixaram conteúdos do seu site, quais irão comprar algo. A Prestus, por exemplo, tem 20.000 visitantes mensais, 10% dos quais se cadastram conosco, o que é considerado um percentual alto de conversão.
No entanto, menos de 5% destes 2000 cadastros se tornam clientes. Ou seja, 95% destes cadastros deveriam ser previstos como apenas Leads, não clientes. Caso o algoritmo se autopenalize demais, uma forma confortável de errar apenas 5% é prever que ninguém desses irá comprar, estimando todos os cadastros como Leads e nenhum como cliente. Com isso, ele acertará mais de 95% das vezes, o que pode ser considerado um sucesso!
É por isso que, mais importante do que essa previsão, é saber qual a probabilidade de cada um dos visitantes cadastrados comprarem. Assim, você poderá usar a seguinte regra: se um determinado cadastro tem 4% de chance de se tornar cliente e sua taxa de fechamento é de 2% ou 3%, então vale a pena ligar para esse cliente e ignorar, até que evoluam, todos aqueles que tiverem probabilidades menores que 1% de fechar.
Dados numéricos: uso campos como número ou como texto?
Vamos explicar alguns componentes muito importantes para o pré-processamento do Machine Learning:

String to number (texto para número): esse componente ajuda em casos em que uma coluna tem textos que são números. Nem sempre, ao salvar em Excel ou CSV, esses campos serão reconhecidos como números automaticamente. Ao selecionar uma coluna para passar por esse componente, os dados passarão a ser considerados numéricos.
Qual a importância disso? O algoritmo de ML não entenderá que uma empresa de 100 funcionários é maior que uma empresa de 10 funcionários se o campo for interpretado como um campo texto. Como o número (valor numérico) de funcionários pode ser importante na predição da chance de um Lead se tornar cliente, o correto é transformar esse campo em número. O mesmo ocorre com o campo “Faturamento da empresa”.

Number to string (número para texto): vamos agora ao exemplo oposto. Digamos que você criou ou possui um campo numérico chamado “DDD” nos seus dados. Não faz sentido analisar esse campo como algo crescente ou proporcional, pois teríamos conclusões erradas, como “o 021 deveria comprar o dobro do 011”. Ou, ainda, iríamos de Sul à Norte, com uma variação numérica “estranha” de DDDs (reduzindo, de 051 em Porto Alegre, à 041 Paraná, à 011 São Paulo, então voltando a crescer para 071 em Salvador e 081 no Recife).
Nesse caso, o componente “Number to string” nos permitirá informar ao ML que “011” é uma categoria de empresas, e não uma quantidade de algo. Assim, todas as empresas “011” (texto) serão agrupadas, como se fossem um tipo de empresa, apenas diferente, e não menor nem maior que as empresas do “021”.
Outro exemplo em que poderia ocorrer o mesmo é o caso do código CNAE, que, embora seja um número, não deve ser interpretado como uma quantidade, e sim como um campo que agrupa cadastros em uma determinada categoria de empresas.
Vale lembrar que o campo principal, para o qual você fará a predição, deverá ser um String, e não um número. Então, se seus dados usam 0 para Lead e 1 para cliente, é importante garantir que esse campo deverá ser um campo “string”, pois só categorias servem para o agrupamento e predição de probabilidade de um cadastro ser 0 ou 1. Se a coluna que você quer predizer já é um campo de texto que contém Lead ou cliente, você não precisa se preocupar.

String Replacer: este componente é útil para padronizar dados. Ele permite, por exemplo, padronizar Leads qualificados como Leads quando se quer uma decisão binária, com probabilidades como Lead ou cliente, como mostrado na figura abaixo.
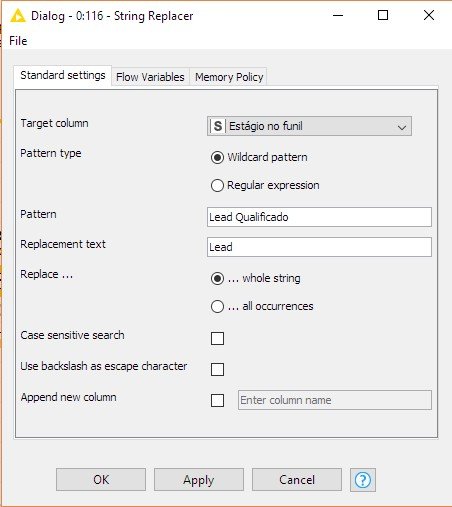

String Replace (Dictionary): como nenhuma big data é organizada como gostaríamos, convém também padronizar alguns dados, como o campo Cargo, para que o número de categorias seja reduzida à 5 ou 10, e os dados não fiquem diluídos demais, com poucos cadastros em cada categoria.
Recomenda-se gerar um campo chamado “Nível do cargo”, por exemplo. Assim, no lugar de “Gerente de produção de laticínios”, você poderá considerar apenas “Gerente”. Vale a pena experimentar com os seus dados e simular sempre. Nesse quesito, o componente chamado de “String Replace (Dictionary)” (substituir texto) no KNIME ajuda muito. Com ele, você pode usar um simples arquivo TXT para agrupar registros e padronizar seus dados.
Veja este exemplo:


Passo 3: Treinar os dados
Vamos agora à fase mais interessante de todo o processo de aplicação do ML ao marketing e vendas. Como neste eBook focamos justamente na Aplicação do Machine Learning em marketing e vendas, vamos nos ater a algoritmos de ML mais fáceis de visualizar. Dentre eles, o que se destaca é o Decision Tree.

Para usar esse componente, vamos começar atribuindo cores aos nossos cadastros. Faremos isso com o componente Color Manager, conforme figura abaixo, que pintará todo Lead de vermelho (insucesso) e todo cliente como verde (sucesso).

Em seguida, chegamos à fase em que é recomendável guardar uma parte dos cadastros que temos, como forma de testar a precisão do algoritmo. Isso se faz, normalmente, separando 5% ou 10% dos dados para funcionarem como teste. Ou seja, esses dados não serão estudados nem aprendidos pelo preditor (Decision Tree Leaner), mas servirão para testar se as predições se confirmam.
Lembre-se de que estamos usando dados supervisionados, ou seja, estamos dizendo para o ML quais cadastros são clientes e quais são apenas Leads. Com isso, pode-se construir uma Matriz de Confusão, que mostra a proporção de previsões corretas versus a quantidade de incorretas (falsos positivos e falsos negativos).
Neste passo a passo, vamos simplificar e permitiremos que 99% dos dados sejam analisados e aprendidos pelo Decision Tree Learner. Veremos se as conclusões fazem sentido, de maneira manual. Se você quer saber mais sobre as razões dessa decisão, pode ler o box Estatística em Marketing e Vendas.

Separar uma parte da população como teste ajuda a evitar overfit: quando o ML aprende praticamente todos os pontos em vez de aprender o comportamento geral. Na figura mais à direita, abaixo, temos o chamado overfit, com um exagero na complexidade desnecessária da fórmula.
Note que, se os pontos continuarem sua tendência de crescimento natural, a equação complexa irá errar a previsão, pois ela prevê que a curva (em azul) se reduz após o último ponto.

Chegamos ao ápice de nossa modelagem por ML: a utilização do nó que irá apreender com os dados e gerar o algoritmo capaz de analisar todos os cadastros e predizer a probabilidade de passarem de Leads para clientes. Vamos configurar esse nó com alguns parâmetros. Preparado para começar?

A configuração é simples: basta escolher qual campo será a categoria (class) que desejamos prever. O campo que contém os valores Lead ou cliente é o campo Estágio do Funil, então o selecionamos. Vamos deixar o Root Split sem forçar nenhuma divisão, como na figura acima, e ver o que o ML descobre a partir dos dados que fornecemos.
Para rodar todo o modelo, basta clicarmos em Executar todos os nós (Execute all executable nodes). É nesse ponto que o algoritmo de fato aprende com todos os dados e estabelece relações entre os diversos campos de todos os cadastros, de modo a prever da melhor maneira a probabilidade de um cadastro estar na categoria cliente.
Passo 4: Validar as conclusões
É hora de navegar a árvore de decisão. Após esse importante componente executar seu aprendizado, você pode clicar com o botão direito e selecionar a visualização da árvore de decisão (“View: Decision Tree View”).

Você verá uma árvore invertida, como a figura abaixo, na qual todos os Leads estão no topo. Podemos ir abrindo um, dois, três ou mais níveis abaixo e comparando as taxas de fechamento dos cadastros até aquele nível.

Notamos que o ML descobriu que o “segmento” de atuação daquele cadastro é o principal ponto para direcionarmos a nossa análise. Todos os Leads foram divididos entre diversos segmentos, com taxas de fechamento (de Lead para cliente) entre 3,2% e 8,3%.
Por meio da proporção entre cores vermelho e verde, também se observa quais segmentos têm maiores probabilidades de fecharmos uma venda. Isso não quer dizer que os segmentos sejam considerados prioritários: note, por exemplo, que há cerca de 876 Leads na categoria Agências de Marketing, enquanto que em outras há mais do que o dobro disso. Portanto haverá mais fechamentos, numericamente falando, em outras categorias.
Um alto percentual de fechamento, nesse caso, só quer dizer que há um particular interesse de agências em fechar projetos com a empresa do que outros segmentos, embora se feche mais negócios em outros segmentos, em valores absolutos.
Podemos baixar mais um nível, clicando nos sinais de “+” logo abaixo de cada segmento. Vamos descobrir segmentos em que o próximo parâmetro (que distingue os cadastros em grupos com maior probabilidade de fechamento) poderá variar:
- No segmento de “Operadoras Telecom” será o campo “Origem da primeira conversão” do cadastro (primeira figura abaixo).

- No segmento de “Agências de Marketing” será o campo “Nível do Cargo”.
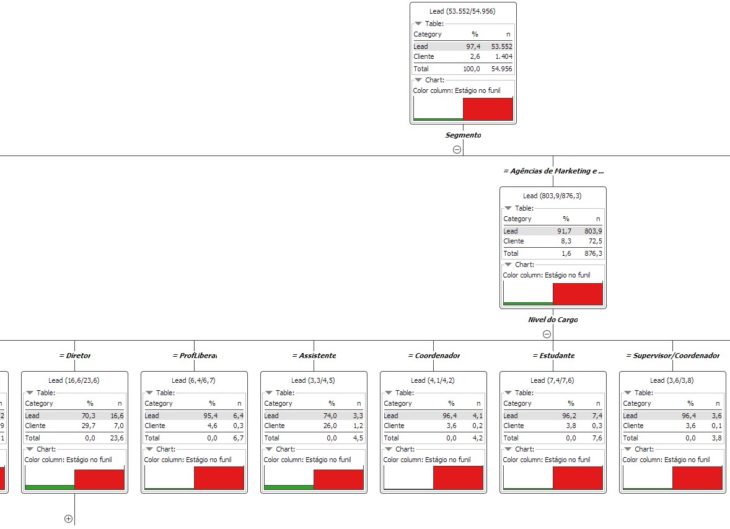
- E no segmento de “Corretores e Representantes” será o nível de “interesse – Lead Scoring”.

Haverá ainda outros diversos níveis, sempre que houver um “padrão” e uma quantidade relevante de Leads agrupada naquela categoria.
Se clicássemos no sinal de “+”, abaixo dos corretores e representantes que têm interesse maior que 17.5, veríamos um terceiro nível de análise/clusterização, que envolve também a “Origem da primeira conversão”. E, mesmo que ela fosse “Tráfego Direto”, num 4º nível, teríamos como verificar as taxas de conversão por estado.
Vamos a um exemplo que vivenciamos aqui na Prestus: pensávamos que o estado da empresa não fosse relevante para adquirir os serviços da Prestus. Afinal, que empresa não precisa atender ligações de clientes ou prospectar? Faz diferença se é uma empresa de SP ou MG? Depois de muitas análises, descobrimos que, para algumas categorias, isso faz total diferença, e que há estados com 10 vezes mais conversões que outros.
Da mesma forma, o serviço cujo interesse trouxe aquele cadastro (se o interesse era em “Ativos” ou “Receptivos”) também resultava em mais conversões em um estado do que em outro. Assim, o ML nos mostrou automaticamente que, na categoria “Empresas de Serviços”, havia pares (binômios) de “Estado+Interesse” com diferenças incríveis! Uma empresa de serviços buscando “Ativos em Brasília” (DF+Ativos) ou outra empresa de serviços buscando “Receptivo em São Paulo” (SP+Receptivo) eram oportunidades que se destacavam, com muito mais probabilidade de fechamento que as demais.
Nesse ponto é importantíssimo validar que essas conclusões fazem sentido. Navegue em todos os ramos da árvore e observe se a maioria dos campos que você imaginava serem importantes para definir se um Lead tem mais chances de se tornar cliente estão presentes, mesmo que esteja sendo útil para uma única categoria.
Caso você sinta falta de algum campo, poderá abrir novamente a configuração do preditor (Decision Tree Learner) e forçar um Root Split, ou seja, forçar que um determinado campo seja considerado no 1º nível e as demais análises sigam nos níveis subsequentes.
Caso não consiga realizar essa divisão, revise os dados originais para ter certeza de que os dados estão corretos e disponíveis. Um nó muito útil para isso é o Table View, que pode ser adicionado e conectado em qualquer ponto do fluxo no KNIME.

Passo 5: Atingindo resultados em Vendas com ML
Finalmente, chegamos no ponto em que queremos a principal conclusão: para cada cadastro de nossa tabela inicial, qual a probabilidade daquele cadastro se tornar um cliente, para que possamos ligar e minerar esse Lead.
Fazemos isso usando um componente chamado “Decision Tree Predictor”, que estimará a probabilidade percentual daquele cadastro se tornar um cliente.

A saída desse componente poderá então ser salva em uma nova tabela de Excel, por meio do componente chamado Excel Writer, que irá salvar os resultados num arquivo como na figura abaixo para que possamos trabalhar os Leads um a um.
Cada cadastro (linha) tem agora duas colunas extras: a probabilidade do cadastro ser apenas um Lead e a coluna de probabilidade do cadastro ser um cliente. Em cada linha encontramos então um valor numérico que, percentualmente, na figura abaixo seria algo entre 1% e 6% de chance de converter como cliente.

Basta agora excluir dessa tabela gerada todos os que já são clientes e filtrar/ordenar, da maior para a menor, a probabilidade de Leads se tornarem clientes.
Pronto! Agora sim você pode partir para ações efetivas com esses seu futuros clientes.
O que faço agora com os Leads mais propensos, de acordo com o Machine Learning? Faça o que as empresas que mais crescem no mercado, com a Resultados Digitais, fazem: minere os seus Leads. Minerar é ligar para sua base de Inbound Marketing. Isso mesmo.
Uso avançado
Lembre-se de que você sempre poderá avaliar a precisão dos resultados deixando uma parte da amostra para validar, e chegará em uma Matriz de Confusão (onde aparecem quantos falsos positivos e falsos negativos ocorreram).
Para isso, poderá então utilizar outros nós, além do Decision Tree Learner, inclusive o componente Matriz de Confusão, para buscar ainda melhores resultados! Outro uso avançado é utilizar o nó PMML Writer para gerar um arquivo PMML, que contém um resumo de todo o aprendizado gerado. Com algum desenvolvimento, um arquivo PMML pode ser aplicado num servidor e processar cadastros indicando, em tempo real, qual a probabilidade de se tornar um cliente.
BÔNUS: Machine Learning e integração com o RD Station Marketing
Para você que utiliza o RD Station, preparamos esta sessão especial com dicas e ideias específicas para você extrair o máximo de seus Leads via Machine Learning usando o KNIME e o RD Station Marketing.
1.Coleta dos dados
Como seus cadastros já estão centralizados no RD Station Marketing, é super simples: vá em Relacionar > Base de Leads > Exportar Base de Leads. Você pode exportar todos os Leads ou uma segmentação deles. Recomendamos que você exporte todos os campos, como exibido na figura abaixo.

Na próxima tela, selecione “CSV adaptado para Excel” e clique em exportar. Ao receber os Leads em seu email, abra a tabela no Excel e crie o campo DDD, por exemplo, conforme explicado no início do tutorial.
Dica: confira se há falhas em algumas linhas do arquivo de exportação. Na conversão CSV para EXCEL, é comum os dados estarem deslocados em relação às colunas corretas. Filtre um campo e elimine todos os dados das linhas com falha. Em uma amostra grande, praticamente não fará diferença e não vale a pena corrigir.
Uso de enriquecimento externo de Leads
Antes de exportar os Leads, você pode conectar o seu RDSM a parceiros de integração que realizam o enriquecimento de dados. A partir do email corporativo do contato, é possível conseguir dados importantes como a Classificação Nacional de Atividades Econômicas (CNAE), que identifica a área de atuação do Lead, o número de funcionários e até o faturamento aproximado da empresa. Tudo isso em campos do próprio RDSM.
2. Pré-processamento dos dados
Recomendamos que você remova a coluna “Número de Conversões”, pois muitos Leads, mesmo os que já se tornaram clientes, continuam gerando conversões, o que distorce o modelo. A predição deve ser precisa para o Lead que está no momento de compra, e não para quem já usa o RDSM.
Por outro lado, vale manter os indicadores de Perfil (A, B, C e D) e de Interesse do seu Lead Scoring. Esses campos podem ser úteis em algumas categorias de interessados por seus produtos e serviços. As análises do ML ajudarão você a identificar aspectos dos cadastros que podem ser incluídos no Lead Scoring, refinando ainda mais a sua classificação.
3. Treinamento dos dados
O Decision Tree Leaner irá realizar as otimizações. Como você já utiliza o RD Station, você pode utilizar o Lead Scoring do RD Station como campos complementares. Porém, quando o assunto é Machine Learning, vale usar com parcimônia os campos “Interesse” e “Número de Conversões”.
A maioria dos clientes continua clicando e interagindo com os seus materiais, o que faz com que ganhem pontos extras no Lead Scoring. Isso pode influenciar no aprendizado da máquina, que entenderá que um contato deve ter muitos pontos para se tornar cliente, por exemplo.
4. Validação das conclusões
Lembre-se de validar as conclusões do Decision Tree Leaner navegando nos diversos níveis que ele sugerir.
Se você está capturando Leads minimamente pré-qualificados (com diversos campos de qualificação), você sabe que os campos “segmento” ou “área de atuação” são um dos principais divisores de águas. Mas há outros como “número de funcionários”, “faturamento”, “Estado” e “DDD” que podem proporcionar uma análise mais precisa do aprendizado de máquina.
5. Atingindo resultados em vendas
Você irá descobrir que, embora os Leads A são quase sempre bons, há muitos Leads bons entre os D e também entre os C!
Por que não criar tags como “P_Cliente” para os Leads com maior probabilidade de se tornarem clientes e começar a nutri-los de uma forma especial?
Conclusão
Longe de ser futuro, o Machine Learning já é realidade: está presente desde os carros autônomos até as publicações selecionadas para aparecerem no seu feed nas redes sociais.
Ao fim deste eBook, esperamos que você tenha entendido o que é o aprendizado de máquina e como ele pode ser útil na estratégia de Marketing Digital da sua empresa.
Além disso, torcemos que o passo a passo para você montar um sistema de Machine Learning capaz de predizer quais Leads têm mais chances de se tornarem clientes ajude você a dar os primeiros passos no uso dessa tecnologia, garanta mais oportunidades de vendas e, consequentemente, mais sucesso para o seu negócio.
Bons resultados e até breve!
Sumário